

Die sich ständig weiterentwickelnde Datenlandschaft stellt Unternehmen vor die Herausforderung Daten so zu verarbeiten, dass sie jederzeit von jedem, der sie benötigt ohne Aufwand gefunden werden können. Durch fehlende Strukturierung und schlechtes Datenmanagement wächst die Menge der Daten, die verwaltet werden müssen, stärker als es sein müsste. Hier kommt die Klassifizierung von SharePoint Inhalten mit Hilfe von künstlicher Intelligenz ins Spiel.
Kyocera Document Solutions hat gemeinsam mit dem Statistikportal Statista 1.000 deutsche Büroangestellte zu deren Informations- und Dokumentenmanagement befragt. Dabei kam heraus, dass die Mitarbeiter täglich fast zwei Stunden für die Suche und Ablage von digitalen oder gedruckten Dokumenten, Vorlagen und Verträgen aufwenden. Weniger als die Hälfte der befragten Personen gaben an, dass Dokumente im eigenen Unternehmen nachvollziehbar abgelegt und schnell auffindbar sind. Weiterhin glaubt lediglich ein Drittel der Befragten, dass die Dokumente vor Veränderung und Verfälschung geschützt sind.
Durch den Einsatz von Künstlicher Intelligenz sind wir in der Lage, Arbeitsprozesse in den Bereichen des Informations- und Dokumentenmanagements zu automatisieren. Unsere Lösung für die automatische Verschlagwortung in SharePoint setzt hierfür folgende Techniken ein:
- OCR – (Optical Character Recognition)
- NLP – (Natural Language Processing)
- Key Phrase Detection
- Automatische Textzusammenfassung
- Mustererkennung
In diesem Blogbeitrag zeigen wir Ihnen die Möglichkeiten und Funktionen dieser Techniken auf.

Die Voraussetzung für automatisiertes Tagging: Qualitative Metadaten
Stellen Sie sich vor, in Ihrem Unternehmen werden 10 Terabyte Daten migriert und müssen anschließend manuell verschlagwortet werden. Und dann müssen natürlich auch jedes Mal, wenn ein neues Dokument erstellt wird, die entsprechenden Metadaten händisch definiert und eingepflegt werden. Wer soll das tun? Der Autor, der zeitlich ohnehin schon stark eingespannt ist und die Daten deswegen nur halbherzig einpflegt? Oder doch ein Mitarbeiter aus der IT mit dem notwendigen technischen Knowhow aber dem fehlenden spezifischen Fachwissen? Beide Möglichkeiten sind genauso teuer wie ineffizient und ein sehr gutes Beispiel dafür, wofür sich KI-Lösungen besonders gut einsetzen lassen.
Die Vereinheitlichung der Daten und die verbesserte Datenanalyse sind entscheidende Vorteile von automatisiertem Tagging. Der neue Prozess analysiert die Dokumente automatisiert, extrahiert die Metadaten und klassifiziert diese anschließend gemäß der definierten Taxonomie. Das sieht dann wie folgt aus:
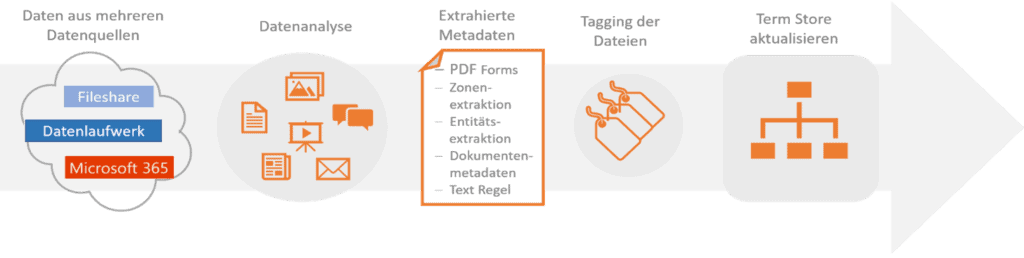
Dabei können die Daten aus verschiedenen Datenquellen, wie beispielsweise Ihrem Fileshare, Unternehmens- bzw. Datenlaufwerk oder aus Ihrer Microsoft 365 Umgebung stammen. Bei der Datenanalyse können sowohl digitale Dokumente, gescannte PDF-Dokumente oder E-Mails verwendet werden. Hierfür werden dann die eingangs benannten Techniken benötigt. Lesen Sie hierzu auch unseren Beitrag: Digitales Dokumentenmanagement Konzept – Vom unübersichtlichen Laufwerk zum modernen digitalen Dokumentenmanagement.
Optical Character Recognition (OCR)
Um Inhalte aus eingescannten Dokumenten oder Bildern für Maschinen sowohl lesbar als auch auswertbar zu gestalten, wird mit Hilfe von OCR das entsprechende Dokument in Zeichen umgewandelt. Hierfür wird zunächst durch eine Layoutanalyse der Seitenaufbau untersucht und Bilder von Text getrennt. Im nächsten Schritt werden Textblöcke in einzelne Sätze zerlegt, welche wiederum in einzelne Wörter gespalten werden. Anschließend werden die Wörter in einzelne Buchstaben unterteilt. Diese einzelnen Buchstaben und Zeichen werden nun vom System eingelesen und wieder in ihre ursprüngliche Reihenfolge gebracht, mit dem Unterschied, dass das System diese nun lesen und zuordnen kann. Nach dieser Indexierung ist es möglich die Inhalte des Dokuments über eine Volltextsuche zu finden, oder diese automatisiert zu vertaggen.
Natural Language Processing (NLP)
Der Einsatz von NLP Technologien ermöglicht Maschinen, die natürliche menschliche Sprache mit Hilfe von Algorithmen und Regeln zu verstehen und zu interpretieren. Durch unterschiedliche Methodiken der Sprachwissenschaften in Kombination mit modernen IT-Systemen und KI, können Inhalte analysiert und Informationen zur weiteren Verarbeitung extrahiert werden. Mit der Zeit eignet sich das System selbständig immer mehr Muster an, um individuelle Frage- und Problemstellungen gezielt bearbeiten zu können. Um diese Arbeit leisten zu können, ist es notwendig, dass das System nicht nur einzelne Wörter und Sätze versteht, sondern auch komplexe Textzusammenhänge und Sachverhalte.
Key Phrase Detection
Mit Hilfe der Keyword-Extraktion werden automatisch Schlüsselwörter identifiziert, die das Thema bzw. den Inhalt eines Dokuments am besten beschreiben. Der Prozess, die relevanten Eigenschaften (Metadaten) auszulesen und zu extrahieren läuft voll automatisiert ab, somit entfällt das händische Eintragen von Metadaten komplett. Diese gesammelten Metadaten können dann an beliebigen Stellen innerhalb Ihres Systems ausgegeben oder abgefragt werden, wie beispielsweise in der Volltextsuche Ihres Digital Workplace.
Automatische Textzusammenfassung
Durch eine Textzusammenfassung können Texte automatisch auf eine vorgegebene Wortanzahl verkürzt werden, ohne dabei die inhaltliche Aussage zu verändern. Da die manuelle Erstellung von verschiedenen Textversionen für unterschiedliche Verwendungszwecke in der Regel sehr zeitaufwendig ist, ergeben sich im Arbeitsalltag zahlreiche sinnhafte Anwendungsbeispiele für das Zusammenfassen von langen Texten.
Mit Hilfe von maschinellem Lernen wird dabei sichergestellt, dass die Sätze mit der höchsten Informationsdichte und der wichtigsten Bedeutung unverändert bleiben. So können sie, beispielsweise im Tagesgeschäft, immer auf den ersten Blick sehen, was wichtig ist und gleichzeitig die Informationsflut auf das Wesentliche reduzieren. Oder Sie erleichtern sich die Arbeit, indem Sie sich aus einer Vielzahl von Berichten, Bewertungen, Reports oder Kommentaren direkt die wichtigsten Kernaussagen, Vor- und Nachteile anzeigen lassen. Vielleicht auch einfach für Ihr nächstes Meeting? Reduzieren Sie den Inhalt Ihres Textes oder Ihrer Präsentation einfach automatisch auf die wichtigsten Kernaussagen.
Mustererkennung
Die Klassifizierung von Objekten, auch maschinelles Sehen genannt, ist ein Teilbereich des maschinellen Lernens und wird verwendet um wiederkehrende Muster in Dokumenten zu identifizieren. Damit Informationen von einer Maschine als visueller Inhalt wahrgenommen werden können, ist eine sehr komplexe Technik notwendig. Die Klassifizierung der einzelnen Dokumente übernimmt ein Algorithmus. Dieser weist jedem einzelnen Objekt eigenständig Metadaten bzw. Tags zu. Hierfür wird das Dokument in einzelne Segmente unterteilt, welchen anschließend ein Merkmal zugeordnet wird. Sollten diese Merkmale noch nicht aussagekräftig genug sein, unterstütz die API bei der korrekten Zuordnung.
Praxisbeispiele für Extraktionstypen
Es gibt verschiedene Möglichkeiten, um Metadaten zu extrahieren. Fünf davon stellen wir Ihnen hier vor:
- PDF Forms: Dokumente enthalten häufig Formularfelder wie Kundenname, Rechnungsnummer, Datum oder Produkt-ID. Deren Inhalte können extrahiert und einer SharePoint-Spalte zugeordnet werden.
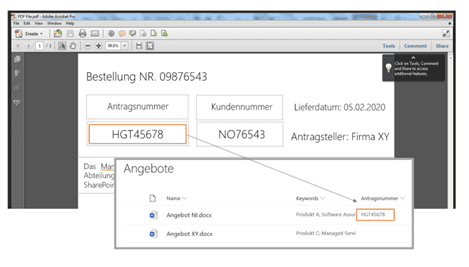
- Zonenextraktion: Ähnliche oder gleichartige Dokumente haben oft das gleiche Layout, wie beispielsweise Rechnungen oder Anweisungen. Es ist möglich diese Dokumente mit Tags zu versehen, indem Text aus bestimmten Bereichen in PDF-Seiten extrahiert wird.
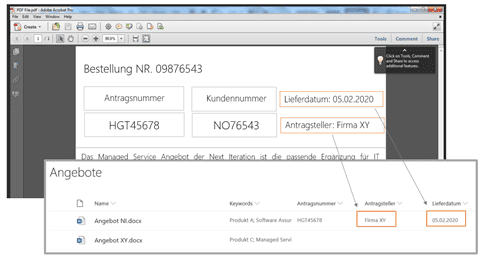
- Dokumentenmetadaten: Sowohl Standard- als auch benutzerdefinierte PDF-Metadaten können extrahiert und SharePoint-Spalten zugewiesen werden. Dies kann auch XMP-Metadaten umfassen.

- Extraktion von Entitäten: Durch die Nutzung von NLP-Diensten ist es möglich, Werte für Informationsobjekte wie beispielsweis den Standort, den Ansprechpartner oder die Firma zu extrahieren.

- Text Regeln: Dokumente können auch durch den Vergleich der Inhalte mit Begriffen aus dem SharePoint Term Store vertaggt werden. Wenn der Inhalt eines Dokuments mit einem Begriff im Term Store übereinstimmt, wird der entsprechende Begriff dem Dokument automatisch als Tag hinzugefügt

Aktualisierung des Term Stores:
Unsere KI-Lösungen vergleichen zum einen Ihre Texte mit den Inhalten Ihres Term Stores, zum anderen ergänzen diese auch automatisch Begriffe, die häufig in Ihren Texten vorkommen. Dadurch ist eine manuelle Pflege des Term Stores nicht mehr notwendig.
Automatisiertes Tagging macht die Verwaltung von Informationen und Dokumenten deutlich einfacher. Daten werden schneller gefunden, weil Inhalte logisch strukturiert sind. Unsere KI-Lösungen unterstützen Sie sowohl bei der Migration Ihrer Inhalte als auch bei Ihrer täglichen Arbeit.
Seit dem 01. Oktober 2020 ermöglicht die neue Syntex KI in SharePoint, den Inhalt aller Firmendokumente zu analysieren um diese mit anderen Anwendungen weiterverarbeiten zu können. Hierfür werden die Dokumente des Anwenders analysiert und die Informationen als Metadaten bereitgestellt, um diese dann anschließend entsprechend ihrem Inhalt einzuordnen. So können Einträge aus Formularen, Adressen, Kalenderdaten und Personennamen von SharePoint erkannt werden. Dadurch kann zum Beispiel geschäftliche Korrespondenz automatisch zugeordnet werden, oder Rechnungen und Lieferscheine automatisch erfasst.
Wenn Sie Hilfe bei Ihrem Vorhaben mit Microsoft 365 oder SharePoint benötigen, beraten wir Sie gerne. Erfahren Sie mehr zu unserer Microsoft Office 365 und Microsoft SharePoint Beratung.


